Thoughts on DevOps - Bottlenecks
 Original source: https://commons.wikimedia.org/wiki/File:Devops-toolchain.svg
Original source: https://commons.wikimedia.org/wiki/File:Devops-toolchain.svg
Years ago, there was a worldwide tendency to adopt ITIL in the IT departments of all organizations, big or small. This, together with the wide adoption (although misunderstood by most) adoption of COBIT led to big and small companies setting up clear pillars, where the focus was on the activity being done, instead of the product or service delivered to the customer.
Table of Contents
“Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure."
This probably looks familiar to a lot of people:
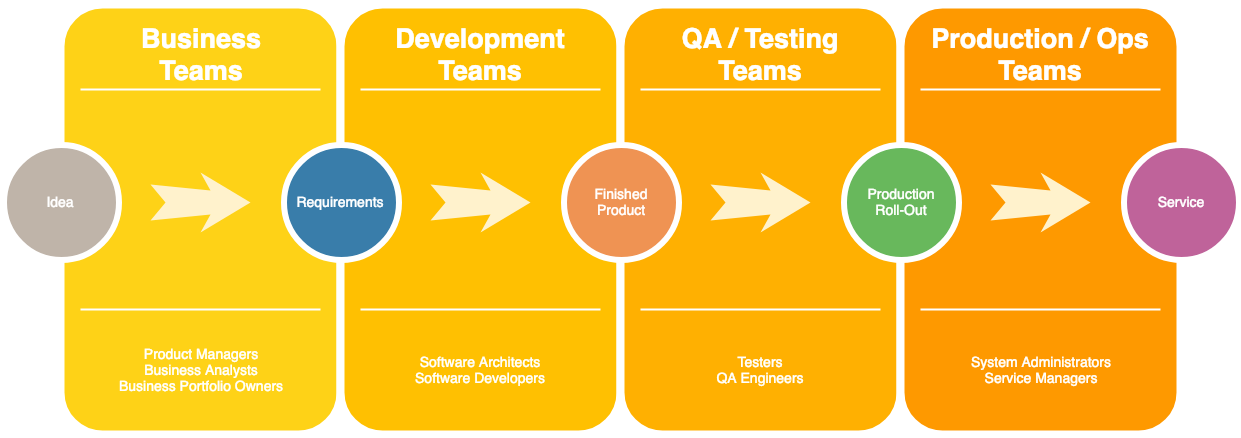 Organizational Silos
Organizational Silos
Of course, the image is extremely simplified. It’s not uncommon to see teams dedicated to creating monitoring checks for the other teams, for example.
Someone looking at that might be tempted to say “Hey, it works!”. I’ve had a colleague tell me “But we’ve been doing it like this for ten years. Why change?”
Introducing the Bottleneck
When working and living inside any system, it becomes really difficult to really see the problems within said system. The same applies to the organizational structure and to the processes used. This is why it’s important to understand that any handover within a system can be a potential bottleneck. It looks like this:
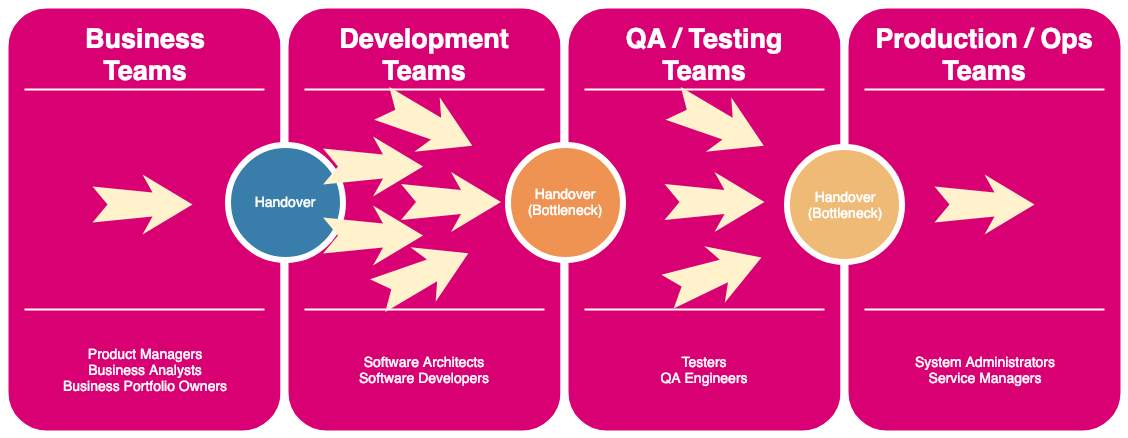 Bottleneck Example
Bottleneck Example
This is only a birds eye overview. You can always zoom in and see that there are a lot of bottlenecks within each silo:
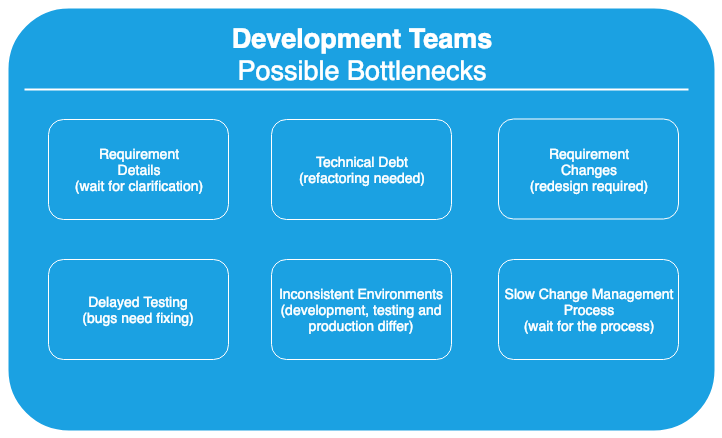 Bottleneck Example - Development
Bottleneck Example - Development
The Rule
“The most common failed performance effort is optimizing something that’s not the bottleneck."
Kat Bush - The Rules of Optimization: Why So Many Performance Efforts Fail
It’s pointless to concentrate on optimizing any part of your organization, as a whole, if there is no progress at the place where the bottlenecks happen. In our example, if we eliminate all the requirements changes (for example, through adoption of short sprints and proper feedback loops with all the stake holders), we will see a direct improvement. But if the team works on improving the documentation (that is currently not a bottleneck), the development process will no experience any change.
The Solutions
Now for the good news: there are a lot of things, on an organizational level, that we can do in order to eliminate bottlenecks. While there isn’t any universal one-size-fits-all recipe, here are some ideas:
Processes
Normally, processes either are generated by policies or by practices. This is where Conway’s Law comes in full effect. When a person interprets a policy, naturally the process will be designed as close as possible to the existing communication paths. The same, if a practice gets documented in a process. It will follow the way the majority already works.
In a newer or smaller company, it’s relatively easy to change a process to eliminate a bottleneck. Everything gets slower in bigger or older companies, where you also have old policies in place.
Policies
Sometimes, the only solution is to make sure that the process owners actually know the policy or to question the way a policy is formulated. A surprisingly big number of people give answers like “We have this process because of our dual control policy” (note: sometimes this is known as “four-eyes-principle” or “double check principle”) or “We cannot give access to the developers because of our segregation of duty policy”. Both answers were, in that particular case, wrong. They were used as an excuse to highlight why it’s impossible to change, to improve. The moment the actual policy was consulted, there were a lot of ways to eliminate the long approvals and and difficult handovers.
However, as someone pointed out, there might be legitimate cases where regulations explicitly require this type of policy. The point I’m trying to make here is to always make sure that you go for the origin of the bottleneck. In a highly regulated environment (think: banking), most (not all) policies have a regulatory requirement behind them. Understand the requirement and you can see how you can improve the policy. Improve the policy and you can improve the process.
Let’s not forget that most policies predate concepts like Continuous Integration, not to mention Continuous Delivery or Continuous Deployment. Of course, it made sense to put in the policy phrases like “The change request must be approved seven working days before the planned change.” (this is actually an optimistic example - I’ve seen a case with 21 working days). If most of the roll-out steps are manual, you need a lot of time to prepare it. If you have one release per year (and sometimes every two years), there will be a long list of one time actions needed during the deployment.
The same applies to the number of approvals needed for a change. Also in the banking sector, I’ve seen a policy requesting approval from all stakeholders for every change. In that particular case, the translation into the process was 36 approvals. And not from teams, but from 36 individuals.
Looking at the dual control policy example, the question I ask myself is “Is it implemented as it’s intended, or is the process an over-complication of the policy?”. The way it was implemented:
- Write code
- Create ServiceNow change ticket
- Upload the diff in SNow
- Wait for the legendary “Reviewer” to sign it off
- Wait for the team creating the package to upload a package based on the diff
- Wait for the deployment team to create a deployment
- … and so on
In between, get more approvals (I’m happy I don’t remember all the details there).
Compare this to a Pull/Merge request, with an automated build / test and deployment pipeline. The strict requirement of having someone else approve the change and trigger the rest of the process is easily met by having someone else review the request.
Communication
Communication gets a special place here, even though it’s normally documented in a process or policy.
“I’ve opened a ticket but they never replied. This was three weeks ago.”
The same as we have a lot of tasks and we handle them based on some priority, other teams also have tasks and duties. It’s always good to follow up on any opened ticket or even sent e-mail. A phone call or even a personal discussion (when possible) goes a long way. Don’t assume that, just because you’ve assigned a work package, it will be handled with top priority.
In the next article, I’ll be talking about organizational structure and the relation to the culture.